Abstract
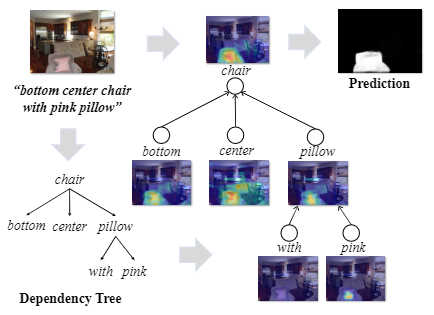
Referring image segmentation aims at segmenting out the object or stuff referred to by a natural language expression. The challenge of this task lies in the requirement of understanding both vision and language. The linguistic structure of a referring expression can provide an intuitive and explainable layout for reasoning over visual and linguistic concepts. In this paper, we propose a structured attention network (SANet) to explore the multimodal reasoning over the dependency tree parsed from the referring expression. Specifically, SANet implements the multimodal reasoning using an attentional multimodal tree-structure recurrent module (AMTreeGRU) in a bottom-up manner. In addition, for spatial detail improvement, SANet further incorporates the semantics-guided low-level features into high-level ones using the proposed attentional skip connection module. Extensive experiments on four public benchmark datasets demonstrate the superiority of our proposed SANet with more explainable visualization examples.
Pengxiang Yan
Computer Vision Engineer
My research interests include deep learning and computer vision, such as segmentation, saliency detection, video analysis, and semi-supervised learning.
